如何爬取天猫评论数据
一、原理
首先在浏览器地址栏中输入 https://www.tmall.com/ 打开天猫商城,任意检索某一商品,以奶粉为例,搜索结果如下图所示:
任意点开其中的某个商品:
这是我们常见的网页,由文字、图片和排版组成。现在将屏幕向下翻,直到看到“累计评价”,即下图中红色矩形圈起来的东西:
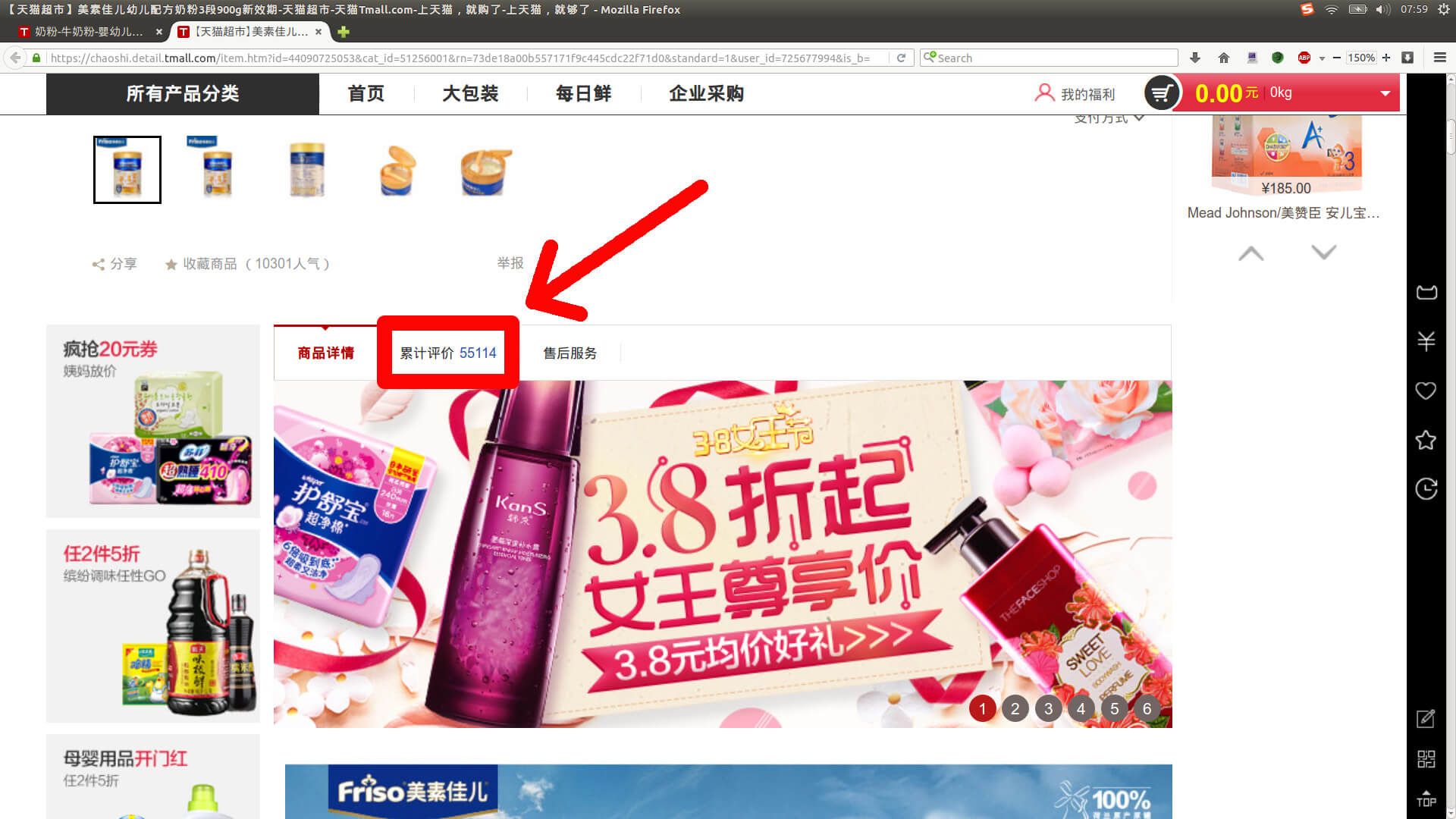
到目前为止这个页面没有任何评价信息,当用鼠标点击“累计评价”后,评价信息才会显示出来。信息并不会凭空产生,那么,这些信息是从哪里来的?显然是从服务器而来。具体的讲便是:
- 浏览器发送请求到服务器,告诉服务器自己需要显示某某商品的评论信息;
- 服务器接到请求,查询某某商品的评论信息;
- 服务器将查询到的评论信息发送给浏览器;
- 浏览器接收到评论信息,将其解析为符合人类阅读习惯的格式,显示在网页上。
现在来看看这一过程具体是如何实现的。需要用到流量监控工具,火狐浏览器按Ctrl+Q或F12可调出此工具。在火狐浏览器中,其界面如下:
页面下方的部分便是流量监控工具,它可以实时的显示该网页与外界通讯的情况,即流量。当然只会监控打开它之后的流量。主流浏览器都内置了此工具,可能会有不同的名称,但功能都大同小异,调出它的快捷键可能不同,但大都为F12。当然也有独立的功能更强大的专业流量监控工具,如WireShark等,不过这次使用浏览器内置的工具足矣。
以下部分强烈建议读者实际操作。网页结构经常会发生巨大改变,若在实践中发现有与下述不符的部分,实属正常。网页在变,但其原理不变。
我们利用流量监控工具来查看浏览器和服务器之间的通讯是如何完成的。在打开流量监控工具的情况下,点击“累计评价”,点击完成后可以看到流量监控工具捕捉到了许多数据包,即下图中红框框起来的部分:
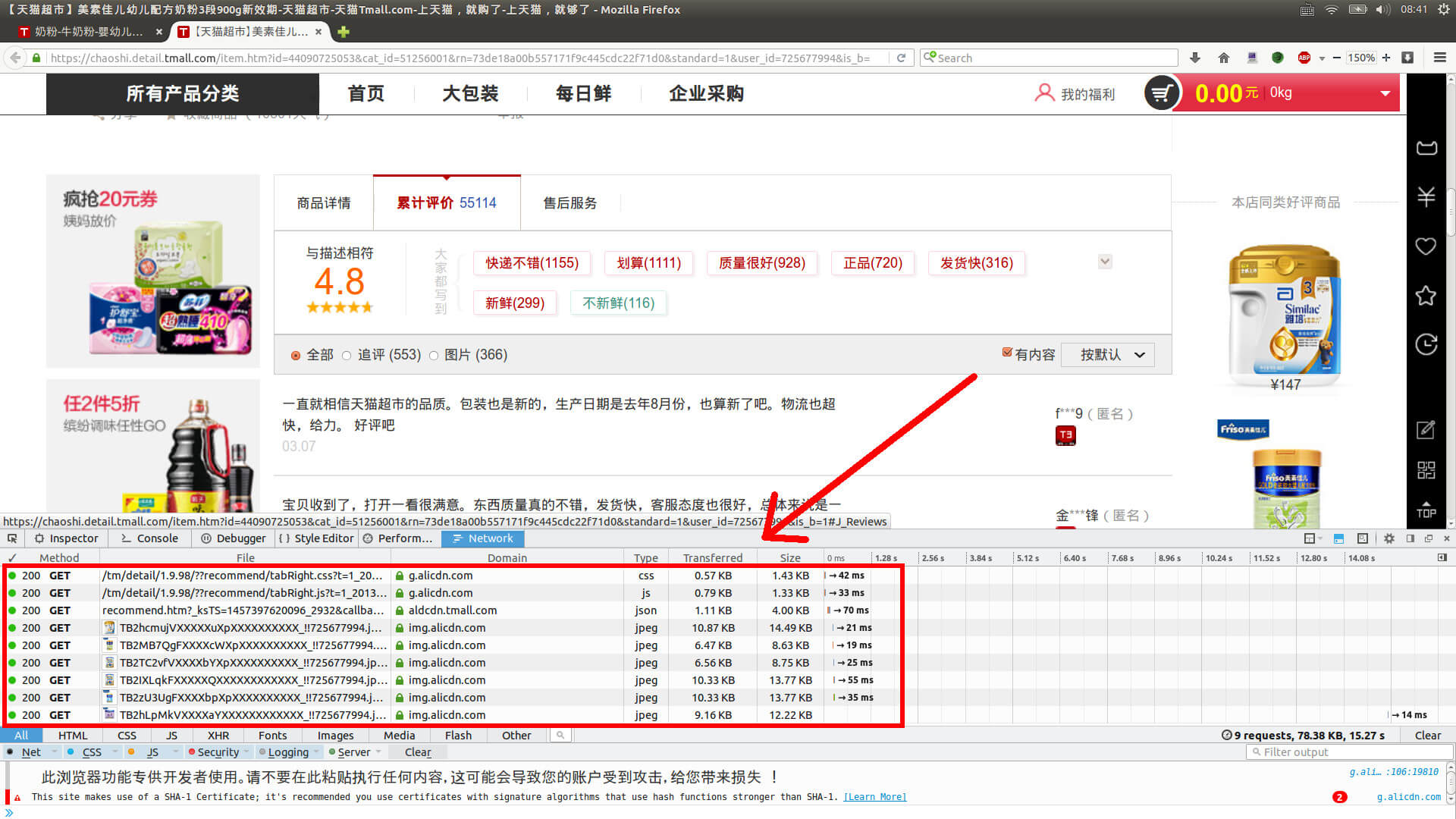
其中每一行都是一个完整的通讯过程,包括了浏览器向服务器发出的请求和服务器返回的数据。可以看到,点击“累计评价”后,浏览器总共发出了9个数据包,请求不同的信息,也接收到了9个数据包,获得了不同的信息。用鼠标选中某一数据包,右键单击,再在弹出菜单中点击”Open in new tab”,就可以看到该数据包返回的文件的具体内容了。
但逐个查看,会发现评论信息并不存在于任何一个数据包中。这是因为流量监控工具只会监控打开它之后的流量,而第一页的评论在我们打开流量监控工具之前就已经加载了。现在我们先点流量监控工具右下角的“Clear”(这样做是为了减少无用的数据包,便于以后分析,不点也可以),然后将屏幕向下翻,点击“下一页”,再次捕捉流量,观察浏览器与服务器之间的通讯:

这次只有两个数据包,而且其中一个是图片,对另一个”Open in new tab”,可以看到如下页图中所示的内容,确实是评论信息。这个文件的后缀虽然是.html,但实际上是一个不规范的Json文件(JavaScript Object Notation,一种轻量级的数据交换格式)。有许多现成的库可以解析该格式的数据。

对比网页中的评论:
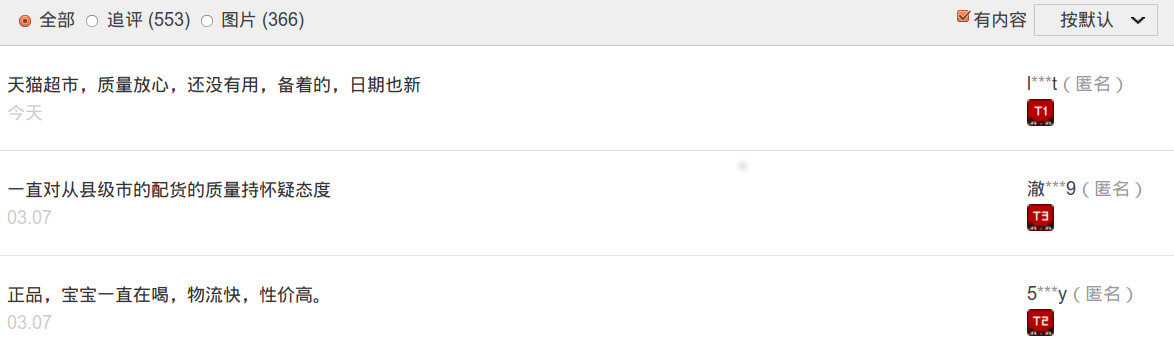
可以看到两者是相符的。
分析第一个数据包,Method为GET,也就是说,它仅仅通过URL来告诉服务器自己需要什么商品的评论信息。来分析下它的URL,是下面长长的一串:
https://rate.tmall.com/list_detail_rate.htm?itemId=44090725053&spuId=324363453&sellerId=725677994&order=3¤tPage=2&append=0&content=1&tagId=&posi=&picture=&ua=251UW5TcyMNYQwiAiwTR3tCf0J%2FQnhEcUpkMmQ%3D\|Um5OcktzSXdDdkhxSnVMeS8%3D\|U2xMHDJ%2BH2QJZwBxX39RaFF%2FX3E3VjBMPRNFEw%3D%3D\|VGhXd1llXGReYFRhX2ZdYltuWWRGeEN5Q31EcEV7QnlMc01xSnNdCw%3D%3D\|VWldfS0SMg41ASEbOxU5WDYSfg98UgRS\|VmhIGCMaOAM4AzgDOgY5Bz8BOQU%2BHiMDPwA6BiYaJx8hGzsHOA0wECoVKAg0Cz4DIxkkHUsd\|V2xMHDIcPAA6GicHPAI4bjg%3D\|WGNDEz0TMw80FCgIMwk1YzU%3D\|WWJCEjwSMgkzEysLMQsyZDI%3D\|WmNDEz0TMws1Dy8bIRU1DDAMMGYw\|W2JCEjwSMgs3Dy8bJhk5DDQONmA2\|XGVFFTsVNQ8xCCgUKRAtDTkGOAxaDA%3D%3D\|XWREFDoUNAg1DzQUKBUtEzMPMgY%2FBlAG\|XmVFFTsVNQkzEy4OMg46DzpsOg%3D%3D\|X2REFDoUNAgzEy8PMw87DzttOw%3D%3D\|QHtbCyULKxAqCjISLhEtEil%2FKQ%3D%3D\|QXhYCCYIKBArFzcDOgAgHCMYLBdBFw%3D%3D\|QntbCyULKxIpETEEPAEhHSUcIBhOGA%3D%3D\|Q3paCiRPKE4zXjhFa0t2VmlWaEh0T3VKfyl%2F\|RH1dDSMNLRUuGjoGOwQ4GCYeJBsncSc%3D\|RXxcDCIMLBUuEzMGPwcnGSIdIB1LHQ%3D%3D\|Rn5eDiAOLn5HekBgVWtSBCQZORc5GSccJh0pfyk%3D\|R35eDiAOLhcrFzcCPAgoFiwXKBZAFg%3D%3D\|SHBQAC4AIHBEfUdnWGNcZ0dzT3ZWalJpS3BLcEtxTXdPcER7T3VVYFp6RHEnBzoaNBo6DjIKMQU7bTs%3D\|SXBNcFBtTXJSbldrS3VNd1duTnBNbVJmRnlMbFZ2TW1VdUxsU21Nck1tUm5Oc1NyTm5PcFBxT29Od1duTm9UdEsd&_ksTS=1457399262078_1440&callback=jsonp1441
看上去很复杂,包含了很多参数。整理一下,按所含参数换行:
https://rate.tmall.com/list_detail_rate.htm
?itemId=44090725053
&spuId=324363453
&sellerId=725677994
&order=3
¤tPage=2
&append=0
&content=1
&tagId=
&posi=
&picture=
&ua=251UW5TcyMNYQwiAiwTR3tCf0J/QnhEcUpkMmQ=|Um5OcktzSXdDdkhxSnVMeS8=|U2xMHDJ+H2QJZwBxX39RaFF/X3E3VjBMPRNFEw==|VGhXd1llXGReYFRhX2ZdYltuWWRGeEN5Q31EcEV7QnlMc01xSnNdCw==|VWldfS0SMg41ASEbOxU5WDYSfg98UgRS|VmhIGCMaOAM4AzgDOgY5Bz8BOQU+HiMDPwA6BiYaJx8hGzsHOA0wECoVKAg0Cz4DIxkkHUsd|V2xMHDIcPAA6GicHPAI4bjg=|WGNDEz0TMw80FCgIMwk1YzU=|WWJCEjwSMgkzEysLMQsyZDI=|WmNDEz0TMws1Dy8bIRU1DDAMMGYw|W2JCEjwSMgs3Dy8bJhk5DDQONmA2|XGVFFTsVNQ8xCCgUKRAtDTkGOAxaDA==|XWREFDoUNAg1DzQUKBUtEzMPMgY/BlAG|XmVFFTsVNQkzEy4OMg46DzpsOg==|X2REFDoUNAgzEy8PMw87DzttOw==|QHtbCyULKxAqCjISLhEtEil/KQ==|QXhYCCYIKBArFzcDOgAgHCMYLBdBFw==|QntbCyULKxIpETEEPAEhHSUcIBhOGA==|Q3paCiRPKE4zXjhFa0t2VmlWaEh0T3VKfyl/|RH1dDSMNLRUuGjoGOwQ4GCYeJBsncSc=|RXxcDCIMLBUuEzMGPwcnGSIdIB1LHQ==|Rn5eDiAOLn5HekBgVWtSBCQZORc5GSccJh0pfyk=|R35eDiAOLhcrFzcCPAgoFiwXKBZAFg==|SHBQAC4AIHBEfUdnWGNcZ0dzT3ZWalJpS3BLcEtxTXdPcER7T3VVYFp6RHEnBzoaNBo6DjIKMQU7bTs=|SXBNcFBtTXJSbldrS3VNd1duTnBNbVJmRnlMbFZ2TW1VdUxsU21Nck1tUm5Oc1NyTm5PcFBxT29Od1duTm9UdEsd
&_ksTS=1457399262078_1440
&callback=jsonp1441
现在很清楚了,以下参数无疑是很关键的:
?itemId=44090725053
&sellerId=725677994
¤tPage=2
itemId是商品ID, sellerId 是卖家ID, currentPage是当前页码。基于此构造如下URL:
https://rate.tmall.com/list_detail_rate.htm?
ItemId=44090725053
&sellerId=725677994
¤tPage=2
将其复制粘贴到浏览器地址栏后打开(当然先要去掉换行),可以看到同样的评论信息。把currentPage的值修改为1,便可以看到第1页的评论,修改为3,便可以看到第3页的评论。简单实验可知,可以看到前99页的评论(当然该商品得有这么多的评论),currentPage=100及以上时的内容与currentPage=99时相同。而若某商品评论较少,不足99页,例如只有45页,那么,currentPage=46及以上时的内容与currentPage=45时相同。
这样,只要知道某商品的itemId和sellerId就可以通过遍历currentPage获取该商品的所有的评论(前99页,人工不停地点“下一页”也最多只能翻到第99页)。
如何得知商品的itemId和sellerId呢?回到搜索“奶粉”后的界面(即第一张插图),把鼠标放在任意商品上,可以在浏览器左下角看到如下的URL:
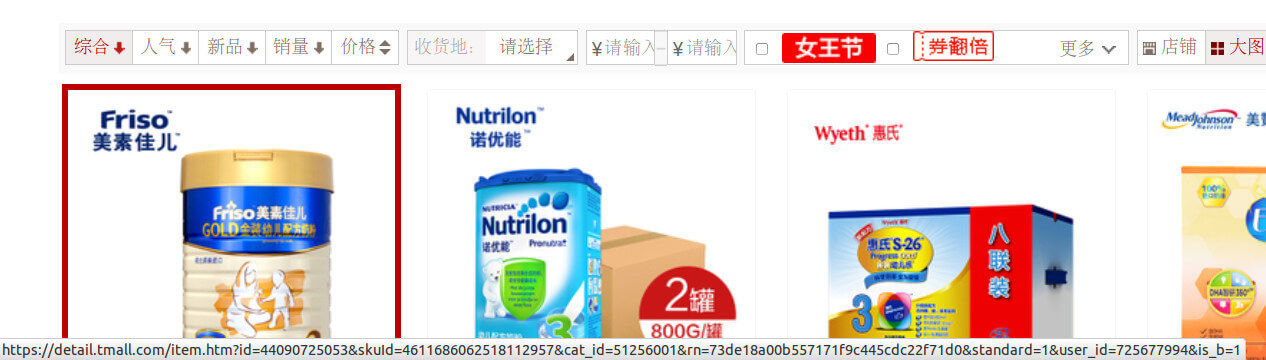
查看网页源码:

放大后:

这个URL指向了商品详情页面,其中的id就是我们需要的itemId,user_id就是sellerId(可能对于天猫来说,卖家就是用户,所以叫user_id)。基于此,只要获取搜索结果页的各商品的URL就可以获得itemId和sellerId了。这件简单的事情用八爪鱼之类的数据采集器可以迅速完成。当然也可以自己写爬虫获取。
####小结:
当我们在天猫商品详情页点“累计评价”时及查看评论翻页时,浏览器用如下的URL:
https://rate.tmall.com/list_detail_rate.htm?
itemId=itemID&sellerId=sellerID¤tPage=N
(省略了其他参数)来告诉服务器自己需要的是那个商品的第几页评论。服务器接到请求,查询该商品的特定评论并将查询结果返回给浏览器,浏览器解析并显示接收到评论信息。
经上面的试验已经知道,不打开天猫纷繁庞杂的电商网页,只发送申请评论信息的URL,产生很少的网络流量,也可以获得评论信息,这对爬取者和被爬取者来说都是一件好事。
以上便是爬取天猫评论信息的原理。总结一下:
- 打开https://www.tmall.com/;
- 搜索某一商品名称;
- 将搜索结果中的所有商品的url爬下来;
- 从url中提取出itemId(id)和sellerId(user_id);
- 利用https://rate.tmall.com/list_detail_rate.htm?itemId=itemID&sellerId=sellerID¤tPage=N
遍历N(0<N<100)获取该商品的评论信息。
需注意第5步中很多商品评论较少,不应以N<100为结束条件,
而应以currentPage=N+1与currentPage=N返回数据是否相同来判断,若相同则认为该商品评论数据已爬取完毕。
二、用Python实现的爬虫
基于以上原理用Python2.7写了一个以爬取千万级天猫评论数据为目标的爬虫,为避免文章过长,就不贴在这了,点
https://github.com/werner-wiki/Practise/blob/master/Python/rateList.py
可以看到。只是初学者的水平,仅供参考。以下是几点说明:
这个程序会对每个商品产生一个日志文件,并且会在爬取完一个商品的评论信息时,删除上上一个商品的日志文件。这样做就避免了爬取1G的数据,产生1G多的日志,而其中有用的往往只是最后几百行。
用到了Python的库pandas来解析Json。而引入正则库re的原因则是发送HTTP请求后接收到的数据并不是标准的Json,需要加工,去掉多余的部分,以使Json可以被正确的解析。
文件itemId.txt 和sellerId.txt 中分别存放itemId和sellerId,一行一个相对应。
考虑到爬虫程序往往会被部署到云主机运行,所以添加了邮件预警机制,即程序意外中断后会发送含有错误报告的邮件到指定的邮箱。在这里使用了配置较为简单的163邮箱作为发件邮箱,收件邮箱可以是任意的有效邮箱。
若想使用该程序,请进行如下操作:
1.配置邮箱
修改在程序开头处的管理员邮箱,这个邮箱会接收程序运行的错误信息和完成信息:
receiver = ["xxx@xxx.xxx",]
正确配置函数 send163mail中的作为发件邮箱的163邮箱:
sender = '************@163.com' #设置发件邮箱,一定要自己注册的邮箱
pwd = '************' #设置发件邮箱的密码,等会登陆会用到
2.配置数据库
首先修改数据库配置部分:
#在此处设置数据库连接信息
db_config = {
"hostname": "localhost",#主机名
"username": "root",#数据库用户名
"password": "root",#数据库密码
"databasename": "test",#要存入数据的数据库名
}
然后进入Mysql执行以下语句创建数据库:
CREATE DATABASE test DEFAULT charACTER SET utf8 COLLATE utf8_general_ci;
数据库名test可以随意修改,但两处要相同。
3.准备itemId.txt 和sellerId.txt
需要准备好各商品的itemId.txt 和sellerId.txt,同一类商品的itemId和sellerId分别存放在同一个文件中并放在以商品类别名命名的文件夹中,如下所示:
.
├── abc
│ ├── itemId.txt
│ └── sellerId.txt
├── def
│ ├── itemId.txt
│ └── sellerId.txt
├── ghi
│ ├── itemId.txt
│ └── sellerId.txt
└── rateList.py
采用如上所示的文件目录结构最后生成的数据库会是这样的:
mysql> show tables;
+----------------+
| Tables_in_test |
+----------------+
| abc |
| def |
| ghi |
+----------------+
表abc中的数据是根据目录abc下的sellerId.txt 和itemId.txt 文件采集的。
4.关于失效
网页结构常常发生变化,使得爬虫程序常常失效。若失效了,请研究HTTP请求返回的原网页,尝试修改
newjson = ''.join(re.findall(r'\"rateList\":(\[.*?\])\,\"searchinfo\"',response))
使正则匹配能顺利完成。当然改变太大了就只好大规模重写代码了。
5.其他提示
在远程主机使用nohup python2 rateList.py &命令(执行后若无命令提示符可按回车)可以确保退出ssh后爬虫程序继续运行。
用ls命令查看日志文件的文件名就可以知道爬取进度。使用tail命令查看日志文件的最后几行,可以方便的追踪日志。
三、更进一步
如何爬取千万级别的天猫评论数据?
1.确定商品名目
根据以往的经验,可以爬取到的一种商品的评论数据大概只有几十万(搜索:“奶粉”,总共80多万条评论数据),假设每种商品全都如此,则也需十几种商品。
2.获取itemId和sellerId
爬取商品名目中所有指向商品详情页的URL,从URL中提取itemId和sellerId,存入文件。爬“奶粉”时总共有大约5000组itemId和sellerId,最终爬取到的评论有大约80万,平均每件商品(即一组itemId和sellerId)对应160条评论。如此计算,总共需62500组左右的itemId和sellerId。估计用时为几小时。
3.抓取评论
itemId和sellerId准备好后按前文所述方法爬取评论信息即可。估计用时为几周至数月。
如此分成几步,每一步都可以实现,最终便可完成千万级别的天猫评论数据爬取。
I’m not that much of a online reader to be honest but your blogs really nice, keep it up!
I’ll go ahead and bookmark your website to come
back later. Cheers